今天來介紹NN的另一個類別,RNN主要是運用在sequence data做預測,也就是任何有序的資料包括語音,句子,時間序列資料(股票走勢)等等,有序資料最大的特點就是資料點與資料點之間是有關連的,所以RNN架構最大的特色就在於“記憶”。
下圖是RNN的大致架構,假設我們今天的input是一句句子:what time is it ?,依序把每個字放入RNN,可以發現在輸入“time”的同時,把“what”放入後產生的output也會一起進入node裡面計算(node裡有兩個顏色),接下來依序如此,到最後放入“?”之後,我們可以看到node裏面有前面所有的output(5個顏色),這就是“記憶”。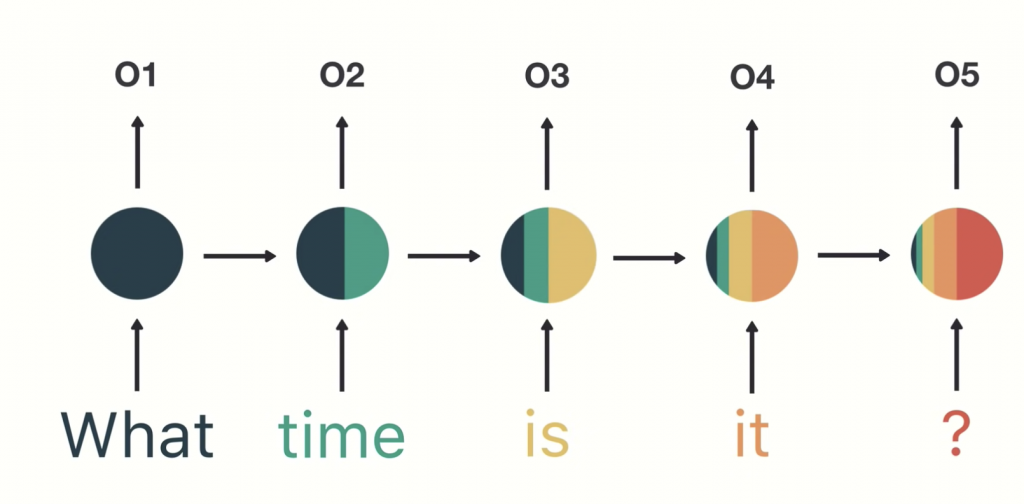
但上圖的結構會有一個問題是,我們會發現越早的input越到後面佔比會逐漸變小(就像人類的記憶一樣越久遠的事情就會越記不清啊),解決的辦法是有另外兩個架構:LSTM與GRU。
佔比會逐漸變小的原因是因為NN透過back propagation來調整w和b的數值,從最後一層往回推到第一層的過程,每次的調整會被前一層(次)的計算影響,步伐會越來越小,這樣就導致最剛開頭的w和b會是非常小的數值以至於在剛開始NN模型學習效率緩慢。
[reference]
https://www.youtube.com/watch?v=LHXXI4-IEns

